Testing vision models with realistic failures
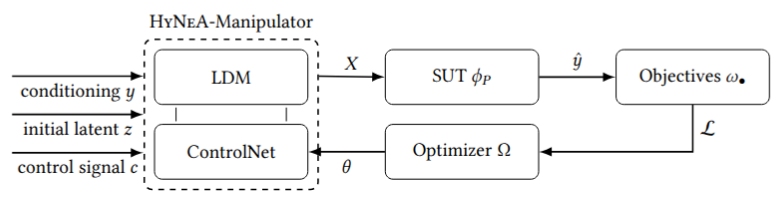
Many vision testing methods create failures that look unrealistic to humans. Traditional adversarial attacks rely on tiny pixel changes, while newer generative methods aim for realism but often introduce visible artifacts or unintended changes. This limits their usefulness for understanding how and why models fail in practice. Qualitative comparisons show that HyNeA produces more realistic failure-inducing images than prior generative approaches such as GiftBench and Mimicry. GiftBench often distorts the overall structure of an image during its search process, making results harder to interpret. Mimicry can generate diverse outputs, but these frequently change multiple aspects of an image at once, leading to ambiguous failures. In contrast, HyNeA preserves the original image structure and semantics while making focused changes that reliably trigger model errors. Because the generated images remain visually coherent and easy to understand, the resulting failures are more informative for debugging and analysis. This makes HyNeA better suited for functional testing, where realistic and interpretable failures are more valuable than synthetic or heavily distorted examples.